这里讨论的问题,主要是基于
HTML的Cucumber + Puppeteer技术栈的UI自动化测试(以下简称UI自动化)中遇到的问题。
UI自动化的一线困境
UI自动化测试在前端的开发测试中,是一件政治正确的事情。
作为一名前端工程师(FE),很少有人敢于说出自己的心声,UI自动化没有什么用处。但大家的身体都很诚实,或者心照不宣的在实际开发中不考虑UI自动化,或者DEMO一下点到为止,或者轰轰烈烈地搞一场虎头蛇尾的UI自动化运动。
实践出真知,一线开发者的真实体验都是用真金白银换来的,需要得到尊重。不过,尊重常识也很重要。高速机枪的杀伤效率一定高于拉栓的步枪,自动化生产线的生产效率一定高于手工作坊。为什么UI自动化测试会比人工的UI测试效率低呢?
政治正确也没毛病,我们需要确立一个基本信念,自动化的效率一定高于人工,而且是数量级压制的差异。
在一线实践中,发现UI自动化效率不能尽如人意的时候,千万不要轻言放弃。要认真研究一下,我们的使用方法是不是科学,成本结构的瓶颈在什么地方?
总结UI自动化实践的制约因素,会发现不管是在用法上,还是在成本结构上,选择页面元素都是一处很重要的瓶颈。
选择页面元素的问题
从UI自动化最小DEMO演示(打开 1 个页面,选择 1 个按钮,点击 1 下),到全流程、全要素UI自动化回归测试,选择 HTML 页面上的元素都是基础中的基础。剧本(Feature)和场景(scenario)从简单到复杂,选择元素的重要性呈线性增长。如果选择的效率低,场景剧本在开发调试上耗时长、成本高,日常维护的返工概率高、频率高、幅度大。在规模较大的复杂UI自动化中,选择元素的效率有一点微小变化,都会给总体成本带来巨大影响,甚至成为制约UI自动化规模的天花板。
在传统前端的 jQuery 时代,使用 $ 函数选择页面元素,基本上是其他代码运行的前提。在 VUE 、 React 等现代前端实践中,代码与 HTML 页面产生了隔离,通过引用对象或回调函数等手段与页面元素交互,不再需要使用 CSS 选择器、 XPath等手段选择元素。从最终的 HTML 页面上看,没有什么可以捕获元素的把柄,弱化了UI自动化选择元素的能力。
HTML 页面直接贴近最终用户,是系统中变动频率比较高的部分。用户交互类的产品需求,又基本上都会带来页面变化,很容易导致日常维护中的UI自动化用例失败。
在页面不断变化的背景下,识别和提炼具有稳定性质的选择器(Selector),是UI自动化成功的关键因素之一。
选择器(Selector)的稳定性质
选择器(Selector)的稳定性质,是相对的、动态的,不总是那么显而易见,需要认真的观察和思考,需要精心的提炼。
HTML 页面上有很多标签(tag)。一般来说,使用标签(tag)做选择器(Selector)很不稳定,不过也有例外。例如,一个管理系统的列表页,上面是查询表单,下面是数据列表,可能整个页面只有一个查询按钮。或者,虽然有多个按钮,但只有一个提交查询请求的 submit 按钮。那就可以把 button 或者 button[type="submit"] 作为稳定的选择器(Selector)使用。
有的文档结构片断,也具有稳定的性质。例如,一个用户端的页面,分为 Header 、 Body 、 Footer 三个部分,在 Header 中有一个搜索条件文本框和一个按钮用来提交搜索请求。那么 header form.search input 用来选择文本框,选择搜索按钮使用 header form.search button ,可能就是一个稳定的选择器(Selector)。
通过认真的观察,我们可以从杂乱无章的页面中,从易变的文档结构中,识别和提炼出具有稳定性质的部分,用来选择元素。找到这种稳定性质后,我们就获得了想要抒发的诗意。但要想写出优美的诗歌,光有诗意可不行,还需要丰富的词汇和对词汇的灵活运用。从另一方面来说,词汇掌握的好,也可以更容易的获得诗意,更容易的识别和提炼页面中具有稳定性质的选择器(Selector)。
选择页面元素的词汇
从UI自动化的角度,我们可以把选择页面元素的词汇不严谨的归纳为 4 类:标识类、属性类、文档结构类和组合应用类。
标识类
有 id 的元素,是UI自动化测试最喜欢的,因为 id 属性在设计上就是用来标识唯一元素的。
样式类(class)在设计上,本来是用来定义外观的,不应该用于选择页面元素。但是,如果某种外观本身具有稳定的性质,那就可以作为稳定的选择器(Selector)使用。例如,在一篇文章的页面,.title 样式类(class)可能就具有用于选择标题元素的稳定性。
说句题外话,虽然 id 和 class 基本上就可以选择到元素了,但加上元素标签(tag)可以增加可读性。例如,input#driverId 表示填写司机ID的文本框,h1.title 表示文章的标题,是一种好的编码习惯。
页面元素的 data-testid 属性,从语义上看就是为测试服务的标识。不管是前端单元测试的遗产,还是专门为UI自动化提供的标识,data-testid 一般都具有稳定性质。当然,关于是否应该使用 data-testid 属性的争论,则是另外一个故事。
属性类
其实 id、 class、 data-testid 都是属性类的特殊形式,也可以用属性类的词汇来表达。
在前端框架、组件库中,或者优雅的业务代码中,前端工程师(FE)经常会语义化的使用一些属性。例如,antd 的 Select 选择器有一个 role="listbox" 的属性,就具有稳定性质。
之所以作为一类单列出来,是因为属性选择器拥有类似正则表达式一样的强大语法,在UI自动化中可以很有效的选择页面元素。
li[item] 可以选择带有 item 属性的一组元素。在属性选择器前加上元素标签(tag),也是为了增加代码的可读性。
a[href="https://ant.design/"] 可以选择跳转到 antd 的超链接。
其他诸如元素的属性中包含某字符串、以某字符串开头、以某字符串结尾等属性选择器用法,就不再一一列举。
文档结构类
相比于标识类和属性类的页面元素选择器(Selector),具有稳定性质的文档结构就不总是那么一目了然,需要更多的观察、识别和提炼。
类似 button,直接使用页面元素的标签(tag),那就是选择所有的 <button />元素了。
button.ant-btn 的样式类(class)前加一个元素标签(tag),并不见得是为了追求代码的可读性,也有可能是为了和 a.ant-btn 做出区分,要选择 <button /> 而不是选择 <a />。
div p 表示选择 <div> 元素内的所有 <p> 元素。只要是在 <div> 的肚子里,元素 <p> 不分层级全部都会被选中。
div > p 选择父元素是 <div> 的所有 <p> 元素。 <p> 元素不但要在 <div> 的肚子里,而且还要是直接子元素,层级更深一些的 <p> 就不会被选中了。
h2 + p 表示 <p> 元素是紧跟在 <h2> 元素后的第一个兄弟元素。注意:紧跟着的那一个 <p> 元素。
h2 ~ p 是选择 <h2> 元素后面的每一个 <p> 元素。
伪选择器也可以用于对文档结构的选择。例如,:nth-child(n) 是指某父元素下的第 n 个子元素。
伪选择器有很多,这里不一一列举。
组合应用类
五色令人目盲,五音令人耳聋。上述选择页面元素的 3 类词汇,独立使用者有之,但更多的是组合应用。
通过用心的观察,识别和提炼出具有稳定性质的选择器(Selector),用简洁的词汇组合表达出来,就可以真的为之四顾,为之踌躇满志了。
我们以 antd Select选择器的基本使用 为例,演示一下页面元素选择词汇的组合表达。
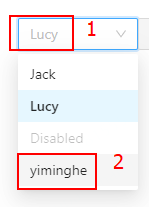
如上图所示,UI自动化一个常见的场景就是点击 antd Select选择器(#1),从下拉列表中选择一个选项(#2,yiminghe),点击选中。
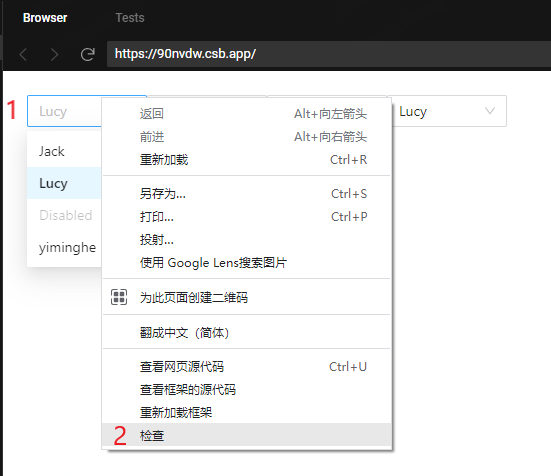
我们右键点击 #1(1),从右键菜单中选择 检查(2),如下图所示:
在 Chrome 开发者工具(F12,开发者工具 > Elements)中观察 #1 对应的HTML代码结构。如下图所示:
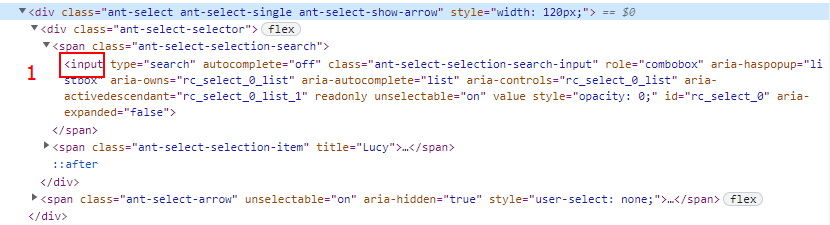
UI自动化中点击 #1,实质上是选择 input[aria-owns="rc_select_0_list"] 后点击, antd Select选择器(#1)的选项下拉列表就会展示出来。
与 HTML 原生的 select 不同,选中 yiminghe(#2)选项并不是那么容易。
还是老套路,在 yiminghe(#2)选项上右键点击,从右键菜单中选择 检查。在 Chrome 开发者工具(F12,开发者工具 > Elements)中观察 yiminghe(#2)选项对应的HTML代码结构。如下图所示:
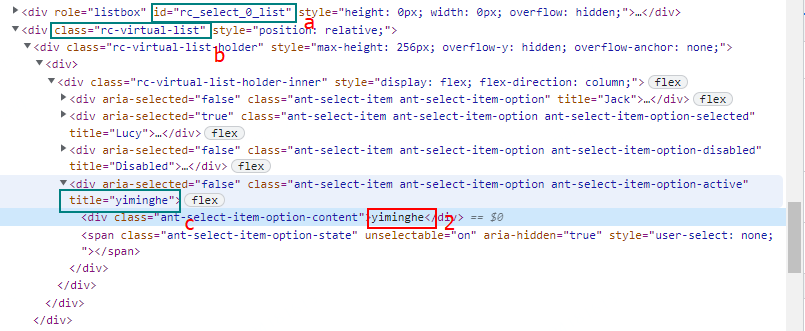
选项(#2,yiminghe)的顶层容器很容易识别,就是 div.rc-virtual-list(b)。非常遗憾,每一个 antd Select选择器都会渲染出一个自己的 div.rc-virtual-list(b)。
再仔细观察,就会发现 div.rc-virtual-list(b)总是紧跟在各自 antd Select选择器的 div#rc_select_0_list(a) 之后。在当前这个场景里, id 和文档结构片断是具有稳定性质的。
进一步观察,可以知道 div.ant-select-item 或 div.ant-select-item-option 可以定位下拉列表中的选项。但是,如果想选中 yiminghe(#2)选项,需要使用属性选择器 div[title="yiminghe"] 。
综上所述,点击 #1( input[aria-owns="rc_select_0_list"]),再选中 #2(div#rc_select_0_list + div.rc-virtual-list div[title="yiminghe"]),就完成了最初设定的UI自动化目标。
无论是哪一类选择页面元素的方法,选择的本身并不重要,最重要的是识别、提炼与页面元素相关的稳定性质。页面元素选择的词汇,只不过是表达这种稳定性质的一个手段。
开发者给选择元素带来的影响
以上讨论的选择页面元素的方法,基本上都强调了UI自动化没有代码侵入性的涵义。假定和开发者之间井水不犯河水,更适用于测试工程师(QA)做UI自动化的黑盒测试。
正如计算机超过 256k 内存,程序员们就不再精心设计内存的使用。自从前端框架和组件库广泛使用以来,尤其是以虚拟 DOM 树为基础的现代前端普及后,前端工程的开发效率有了质的提升。与此同时,大家对 HTML 标签(tag)的语义化使用,却不如早前那般重视。
除了编写优雅的 jsx 代码,作为优雅的前端工程师(FE),还应该特别关心 HTML 标签(tag)、属性和文档结构的语义化表达。按钮要用 <button class="ant-btn" />,而不是 <a class="ant-btn" />。无序列表要用 <ul />,有序列表用 <ol />,段落就用 <p />。如果需要对自己的主题做个解释,就使用 <div title="主题" />。页面元素的层次结构也如是,是父子关系的内容就用标签(tag)的父子结构表达,是兄弟关系就用标签(tag)的兄弟关系表达语义。
如果开发者(前端工程师,FE)积极参与进来,设计出优雅的前端代码,具有良好的可测性,UI自动化就会吹进一股亚平宁半岛的风。
与测试驱动开发(Test-Driven Development,TDD)先写单元测试用例再写代码实现类似,行为驱动开发(Behavior-Driven Development,BDD)也应该是先写UI自动化的场景剧本,再进行前端代码的开发。既然是先有剧本(Feature)和场景(scenario),就会反向驱动前端工程师(FE)精心设计具有良好可测性的选择器(Selector),就会实现良好的语义化文档结构和必要的 data-testid 等可测性属性。
前端组件单元测试中,也需要准确选择元素才能断言,所以良好的单元测试也会为UI自动化选择页面元素提供良好的支持。
开发者还可以提供页面元素选择的框架级增强。例如,可以根据需要增加 XPath 选择 HTML 页面元素的能力,可以引入 Testing Library 等工具库,强化UI自动化选择页面元素的能力。
Chrome 开发者工具(F12)的辅助作用
充分利用 Chrome 开发者工具(F12)提供的辅助能力,可以提高选择页面元素的效率。
选择器(Selector)辅助分析
如下图,在需要分析的页面元素(1)上点击右键,从右键菜单中选择 检查(2),即可用来分析页面元素。

利用 Chrome 开发者工具(F12),复制出页面元素的选择器(Selector),如下图:
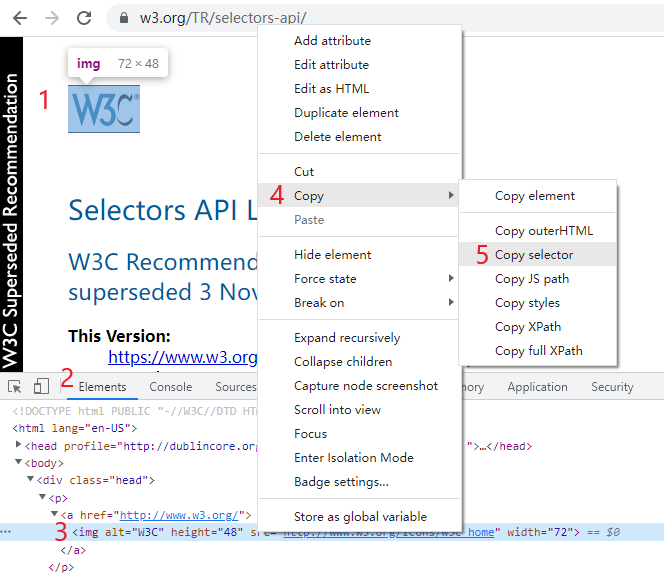
在页面元素(1)对应的 Elements 标签(2)中的元素结构(3)上,右键菜单选择 Copy (4),选择 Copy selector (5),就可以复制出页面元素(1)的选择器(Selector)。
这个方法获复制出的选择器(Selector),缺少UI自动化所需要的稳定性质,很难直接使用。但是,有很重要的参考价值,能从中识别和提炼出具有稳定性质的选择器(Selector)。
选择器(Selector)的验证
对于比较复杂的页面元素选择器(Selector),我们需要验证一下,才能用于UI自动化。毕竟,如果捕获不到指定的元素,选择器(Selector)长得再好看也没有用。
Puppeteer 技术栈选择元素是由 document.querySelector 、 document.querySelectorAll 实现的,可以在 Chrome 开发者工具(F12)中使用同样的方法来验证选择器(Selector)是否有效。如果开发者对选择元素提供了框架级增强,也可以由其提供更多的验证方法。
在这里,我们且只考虑CSS选择器的验证,以 document.querySelector 为例,如下图:
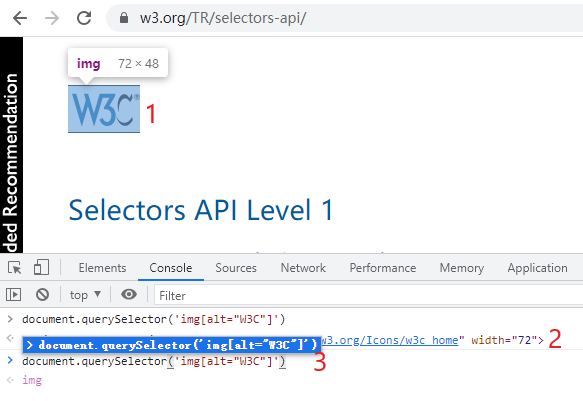
如果选择器(3)正确,对应的页面元素(1)会有反选效果。 回车确认后, Console 控制台可以回显页面元素的HTML代码(2),鼠标移动到(2)后,选中的页面元素(1)也会有反选效果。
除了上述方法验证外,还可以在 Chrome 开发者工具(F12,开发者工具 > Elements)中使用 Ctrl + F 调出查询文本框(1),把选择器(Selector) Copy 进去验证。如下图:
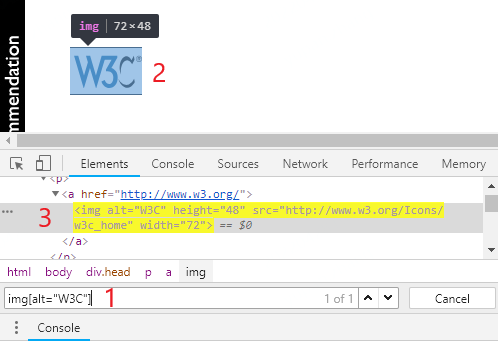
以上的 2 个方法,可以验证页面上的静态元素。有些元素是交互中才会动态出现的,就不太方便验证。
这种情况下,可以为动态元素指定一些比较夸张的验证样式来验证。如下图:
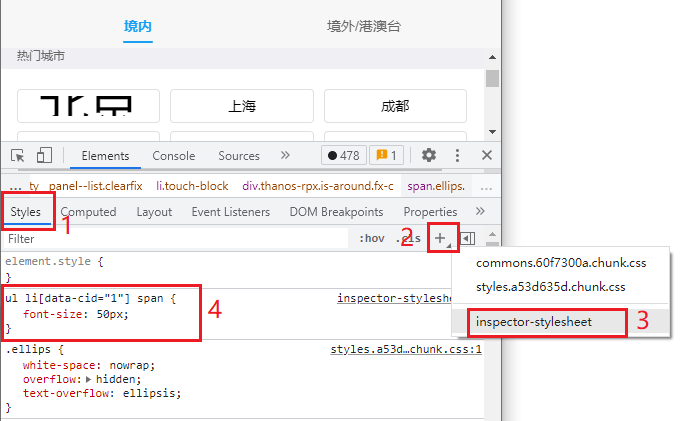
在 Chrome 开发者工具(F12,开发者工具 > Elements)的 Styles 视图(1)右侧点加号(2),选中 inspector-stylesheet(3),在视图中添加 CSS 选择器(Selector)(4)。在这个样式中,可以写比较夸张的样式,例如很大的字(font-size: 50px)。当观察到页面元素产生了预期的夸张变化后,说明你写的选择器(Selector)是对的。
这个验证方式,也有不适用的场景。例如,CSS 选择器优先级的权重不够高,即使是正确的选择器(Selector),元素样式也不会出现预期的夸张变化。
在UI自动化测试中,选择页面元素是一件充满诗意的工作,探索和研究不可能一劳永逸。
参考文档
重要参考
- 【重要】Puppeteer CSS 和
text/、xpath/、aria/、pierce/选择器 - 【重要】CSS 选择器可用写法参考
- 【重要】CSS选择器优先级
- 【重要】内置的 XPath 选择器可用写法参考 (xpath/)
- 【重要】扩展的 jQuery 选择器可用写法参考 (jQuery/)